

OCR 技術解説
「当社方式を例にとって、文字の認識方法にるいてご案内します。」
OCR 技術解説 文字の読み取り・認識について
はじめに
PCのCPU性能の向上に伴い、PC上で文字を認識するOCR(Optical Character Recognition/Reader)ソフトが商品化され、多くのユーザーに活用されています。OCRソフトは、ワープロやデータベース、表計算ソフトなどと比較すると、その内部処理(文字をどのように認識しているのか?)が一般の人には想像しにくいところです。
これまでPCのソフトとして発展してきた分野としては、決った手法の計算処理を、速いスピードで実行するという、人間にとってきわめて不得意な部分でした。 人間にとって得意な分野であるがコンピュータには弱い分野であるパターン認識をソフトウェアで実現したのがOCRソフトです。
ここでは、文字認識ソフトウェアであるOCRソフトに焦点をあて、あまり知られていない文字の認識方法や技術水準について、当社の方式を例にとって、わかり易く説明します。

OCR技術解説 第1ステップ:画像取り込み
私達は、新聞や雑誌に印刷されている文字や街中の看板に書かれている文字などを簡単に読むことができます。しかし、PCで行うとなると次のようなステップが必要となります。 新聞や雑誌などのOCR(文字認識)したい原稿をイメージスキャナやデジタルカメラを使用して、PC内に取り込みます。 新聞をイメージスキャナを介してPC内に取り込み、ディスプレイに表示した例が図1です。 ▼図1--●新聞をスキャナで読み込んだ画像 
OCR技術解説 第2ステップ:レイアウト解析
図1を見ると、表題や図があり、文章については、いくつかの段組みから構成されていることがわかります。 OCR(文字認識)を行うためには、図1の中から文字の部分を見つけて、読む順序を決めてやる必要があり、この処理をレイアウト解析と言います。 図1の画像のレイアウト解析を行ったものが図2です。 ▼図2--●レイアウト解析を行った例 
OCR技術解説 第3ステップ:行の切り出し
第2ステップで見つけた文字の「かたまり」の部分を拡大したものが図3です。 次に、図3の画像を同図に示すように1行ごとに分解します。この処理を行の切り出しと呼んでいます。 ▼図3--●文字領域で「行」の切り出しを行った例 
OCR技術解説 第4ステップ:文字の切り出し
次に図3の画像の1行に注目して、1行を図4に示すように1文字ごとに分解します。この処理を文字の切り出しと呼んでいます。 この処理は図4に示すように、左右の線を上から下に移動しながら、この線が文字と交差する数をカウントして、この値が「0」(白のすき間)のところを文字と文字の区切りとして判断する方法がとられています。 しかし、日本語の場合「三」や「高」などのように、この方法だけでは1つの文字として判断できない場合や、原稿の文字間隔が狭い場合は、正確に1文字を切り出すのは結構難しく、高度な処理が必要となります。 ▼図4--●1行から「文字」の切り出しを行う方法 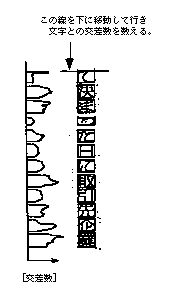
OCR技術解説 第5ステップ:文字認識
ここでは1文字ごとの認識を行うことになりますが、印刷された文字についてよく調べてみると、個々の文字について、 (1)文字の大きさ (2)文字の字体(明朝体・ゴシック体・教科書体など) (3)文字のつぶれ、かすれ などが文書によって異なっていることが判ります。 これらの変動に対して、正確にOCR(文字認識)を行うために、図5に示すような、正規化、特徴抽出、マッチング、知識処理という順で処理をすすめて行きます。 ▼図5--●一般的な文字認識処理手順 
(i)正規化
OCR(文字認識)したい1つの文字を一定の大きさ(日本語の場合一般に正方形)に変換します。この処理は文字の変形(縦長、横長など)を吸収することと、一定の大きさにすることによって、後の処理を簡単にする目的で行います。 図6は正規化処理を説明したものです。 ▼図6--●正規化処理 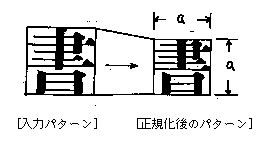
(ii)特徴抽出
初期のころのOCR(文字認識)は、正規化された状態の文字パターンを、同じ形態で、あらかじめ登録されている標準パターンと図7に示すような単純な「重ね合せ」法によって比較をして、答を出していました。 しかし、この方法だと、「文字の傾き」や「字体」、「かすれ、つぶれ」などの変動を吸収するのが難しく、決まった字形の少数の文字以外では高い認識精度を得ることは困難でした。 その後、文字の形をそのまま比較して認識する方法から、いろいろな変動を吸収して、正確にOCR(文字認識)することができる方式(一旦、文字の「特徴」に変換する方式)がとられるようになって来ました。 ▼図-7-----●「D」と「A」を「重ね合せ」により一致度を調べている例 (完全に一致した場合に認識されたことになる)  図8は最近広く使用されている、文字の方向成分を利用した特徴の概念を示したものです。 すなわち、(i)で正規化された文字を図9のような上下、左右、斜め方向の4つの成分に分解して、メモリー量や処理時間を考えて、4つの成分を7×7程度までに圧縮したものを個々の文字の特徴として抽出します。 この時点で、1つの文字は(7×7)×4=196個の特徴値に変換されたことになります。(図8) ▼図8--●特徴抽出
図8は最近広く使用されている、文字の方向成分を利用した特徴の概念を示したものです。 すなわち、(i)で正規化された文字を図9のような上下、左右、斜め方向の4つの成分に分解して、メモリー量や処理時間を考えて、4つの成分を7×7程度までに圧縮したものを個々の文字の特徴として抽出します。 この時点で、1つの文字は(7×7)×4=196個の特徴値に変換されたことになります。(図8) ▼図8--●特徴抽出  ▼図9●4つの方向(1~4の方向に近い線分に分解する)
▼図9●4つの方向(1~4の方向に近い線分に分解する) 
図8は最近広く使用されている、文字の方向成分を利用した特徴の概念を示したものです。 すなわち、(i)で正規化された文字を図9のような上下、左右、斜め方向の4つの成分に分解して、メモリー量や処理時間を考えて、4つの成分を7×7程度までに圧縮したものを個々の文字の特徴として抽出します。 この時点で、1つの文字は(7×7)×4=196個の特徴値に変換されたことになります。(図8) ▼図8--●特徴抽出 ▼図9●4つの方向(1~4の方向に近い線分に分解する) (iii)マッチング
OCR(文字認識)を行うためには、(ii)で説明した「特徴」を使って、認識したい文字をすべて、あらかじめ登録しておくことが必要です。これを「標準パターン」と呼んでいます。 「標準パターン」は、いろいろな字体(明朝体、ゴシック体、教科書体など)や「かすれ」、「つぶれ」文字の認識を安定して行うために、いろいろな状態で印字された文字を平均化して作られています。 その上で認識したい文字を(i)、(ii)を経て処理された「特徴」に変換して、どの文字(標準パターン)に近いかの計算を行うわけです。 ▼図10●ユークリッド距離(D)  2次元パターン間の距離(似ている度合い)を計算する方法はいくつかありますが、一般に図10に示すようなユークリッド距離という方法が用いられています。 対応する座標ごとに以下のような計算を行います。
2次元パターン間の距離(似ている度合い)を計算する方法はいくつかありますが、一般に図10に示すようなユークリッド距離という方法が用いられています。 対応する座標ごとに以下のような計算を行います。  この方式により、入力された文字の特徴とすべての標準パターンとの距離計算を図11に示すように行います。 そして、標準パターンと距離計算した結果、最も距離の小さいものが、認識結果となります。 この処理をする場合に、距離の1番小さいものだけでなく、第2~第5位くらいまでの結果も合わせて候補文字として表示し、誤読文字の訂正に使用したり、次の知識処理で使用する方法がとられています。 ▼図11--●マッチング処理 入力パターンの「特徴」と「標準パターン」の1~4の方向成分毎にユークリッド距離を計算し、その値が最も小さい「標準パターン」が認識結果となります。
この方式により、入力された文字の特徴とすべての標準パターンとの距離計算を図11に示すように行います。 そして、標準パターンと距離計算した結果、最も距離の小さいものが、認識結果となります。 この処理をする場合に、距離の1番小さいものだけでなく、第2~第5位くらいまでの結果も合わせて候補文字として表示し、誤読文字の訂正に使用したり、次の知識処理で使用する方法がとられています。 ▼図11--●マッチング処理 入力パターンの「特徴」と「標準パターン」の1~4の方向成分毎にユークリッド距離を計算し、その値が最も小さい「標準パターン」が認識結果となります。 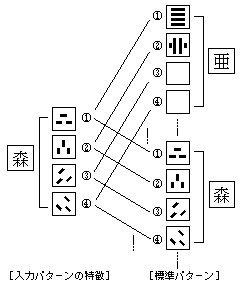
2次元パターン間の距離(似ている度合い)を計算する方法はいくつかありますが、一般に図10に示すようなユークリッド距離という方法が用いられています。 対応する座標ごとに以下のような計算を行います。 この方式により、入力された文字の特徴とすべての標準パターンとの距離計算を図11に示すように行います。 そして、標準パターンと距離計算した結果、最も距離の小さいものが、認識結果となります。 この処理をする場合に、距離の1番小さいものだけでなく、第2~第5位くらいまでの結果も合わせて候補文字として表示し、誤読文字の訂正に使用したり、次の知識処理で使用する方法がとられています。 ▼図11--●マッチング処理 入力パターンの「特徴」と「標準パターン」の1~4の方向成分毎にユークリッド距離を計算し、その値が最も小さい「標準パターン」が認識結果となります。 (iv)知識処理
(iii)のマッチング処理では、たとえば、「夕(漢字)」と「タ(カタカナ)」や「力(漢字)」と「カ(カタカナ)」などを認識することは困難です。人間の場合も、これらを識別するには、文字列の前後関係を見て判断しているのです。 簡単に説明しますと、このように日本語の単語情報やもう少し広い意味での言語情報を使用して、より正確な認識を行うことを「知識処理」と呼んでいます。 知識処理では認識された文字列の候補文字から、あらかじめ登録してある単語辞書と照合して誤読した部分を自動的に訂正するという方法が一般的に使用されています。 しかし、人間は多少誤読した部分があっても、その部分を「前後関係」や、「この文章はどのような状況での文章なのか」などの情報を使って推測することができますが、現状の「知識処理」は、まだこのレベルには至ってはおりません。 以上に示しました(i)~(iv)の処理により、個々の文字認識が行われ、その結果が得られるのです。 ▼図---12●知識処理 (iii)で得られた候補文字の情報を使用して図12のように行います。 「東」を「束」と誤認識したが、2位に「東」があったので、「東京」という単語辞書により自動訂正される。 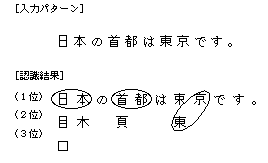
OCR技術解説 第6ステップ:フォーマット出力
以前は、第5ステップまでで文字認識は終了ですが、認識結果を元の文書の形と同じように出力し再利用できるように、この第6ステップの処理に進みます。 最近では、ほとんどのOCRソフトがWord、Excel、一太郎、PDF、HTMLなどのフォーマット出力に対応しています。これらのフォーマットに対応することにより、元の原稿とほぼ同じ形の電子化原稿を得ることができます。
OCR技術解説 まとめ
以上が、活字文書の文字認識が、どのように行われ、その結果がどのような形で出力されるのかについての一連の流れです。 当初は、これらの一連の処理をPCのソフトで行うことは、CPUスピードやメモリ容量の点で非常に難しく、ハードウェアによって実現していました。CPU性能の向上やメモリの大容量化は活字文書OCRソフトの進化を加速し、最近では数千~2万円の商品が主流となり、ユーザー層も非常に拡大してきています。ちなみに、これらの低価格な活字文書OCRソフトにおいても、先に説明した第1ステップから第6ステップの処理を行っています。 以上、活字文書を認識する方法を中心に説明をしましたが、手書き文字の認識に関しては、活字文字以上に書く人によって文字の変動(ばらつき)が大きく、容易ではありません。 手書き文字認識では、活字文字を認識する場合の倍以上の「特徴」を使用し、認識方式もより複雑で高度なものを使用していますが、これについては説明を省略させて頂きます。


