
機能-OCR識別
機能-OCR識別
OCRには活字文書OCRソフトウェアで実績のある高性能認識エンジンを搭載しました。OCR認識言語は日本語/英語となります。指定範囲内の識別結果から文字列を高速検索(一致・部分一致)し、文書や帳票を自動分類/振分します。
適用事例1
文書や帳票内に含まれる「タイトル」や「名称」をキーにOCR識別を実施し、各タイトルごとに自動分類/振分します。
(例)「決算報告書」「契約書」「会議議事録」をタイトルで分類

(例)「決算報告書」「契約書」「会議議事録」をタイトルで分類
適用事例2
文書や帳票内に含まれる「文字列」をキーにOCR識別し、指定した「文字列」が含まれる文書や帳票を自動分類します。
(例)キーワード「○○○○」が含まれる文書を指定のフォルダへ
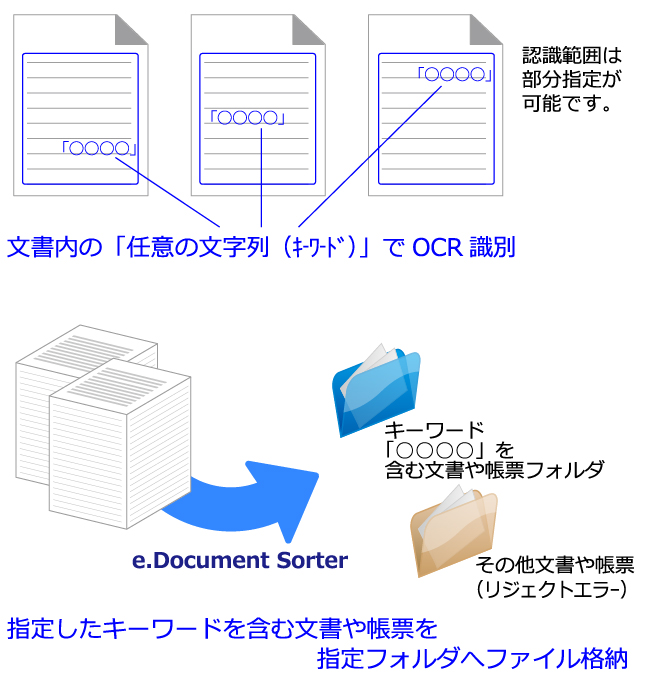
(例)キーワード「○○○○」が含まれる文書を指定のフォルダへ
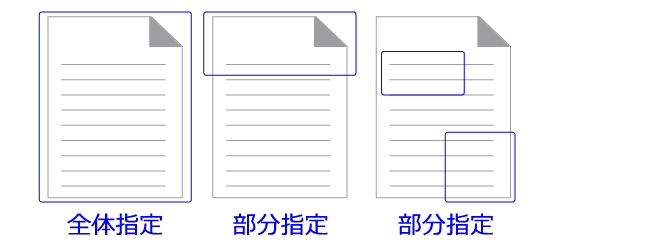
識別対象領域
OCR識別の対象となる領域(文書全体/任意指定位置)の設定が可能です。
条件設定
識別対象となる文字列は、完全一致、部分一致、数量範囲指定など、判定種別が設定できます。また、複数の条件設定を組み合わせた処理が可能です。利用可能な条件式は([and] [or] [not])となります。
例:(条件名1 and 条件名2)and not 条件名3
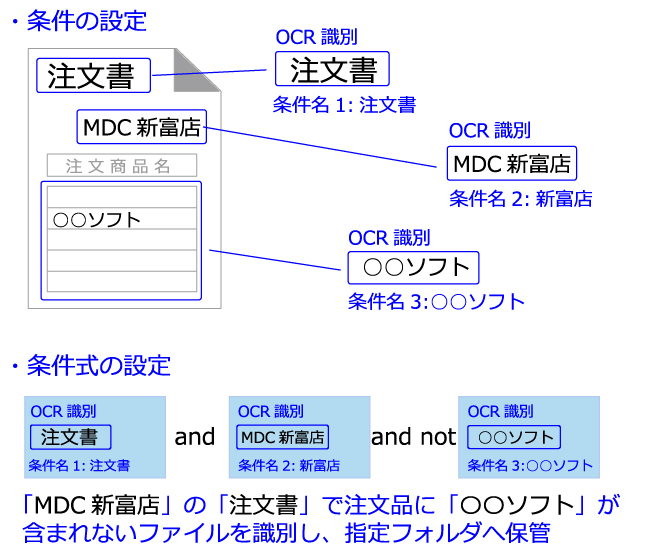
例:(条件名1 and 条件名2)and not 条件名3
学習機能
OCR識別時の処理性能向上のための文字学習が可能です。認識できない特殊な字体・フォントの認識を可能にします。
認識対象言語
識別対象言語は漢字(JIS第1水準、第2水準420文字)、ひらがな、カタカナ、 アルファベット、数字、記号等3,700種


