


文字認識技術の黎明期
文字認識技術の黎明期
文字認識は、当社技術では、OCR技術解説にて説明をしてきた方法によって行っていますが、活字文書を例にとってみても、世の中にはいろいろな種類の文書があり、これらを100%の精度で文字認識することは非常に困難です。
日本語にはひらがな・カタカナ・漢字と様々な字種の認識技術が必要となり、更に手書き文字の認識技術が加わり、様々な技術開発が行われてきました。ここでは文字認識技術の黎明期の技術を見ていきます。
文字認識の技術水準
・定ピッチに印刷、印字された文書
・日本語と英語が混在している文書
・印字品質の良い文書
については100%に近い精度で文字認識することができます。
しかし、
・不定ピッチに印刷、印字された文書
・低画質文書(FAX、コピーした原稿)
などになると文字認識率が低下する場合があり、
・フォントの識別
・文字と非文字の区別
・確実なリジェクト
・背景下の文字
・見出しなどの飾り文字
などの文字認識は、難しいと言われてきましたが、最近では画像処理技術の進歩により、徐々に可能となりつつあります。
すなわち、新聞のように複雑な段組みで、文字と文字の間隔も狭い文書については難しく、普通に印字したワープロ原稿などのように、文字と文字の間隔の空いている文書は一般に認識し易いということが言えます。
このように、現状の文字認識技術のレベルは人間と比較するとまだまだ低いところもありますが、文字認識し易い文書も世の中にはたくさんあり、技術的にも日々進化していますので、「上手に使う」ことにより、非常に便利なソフトウェアであると言えるでしょう。
・日本語と英語が混在している文書
・印字品質の良い文書
については100%に近い精度で文字認識することができます。
しかし、
・不定ピッチに印刷、印字された文書
・低画質文書(FAX、コピーした原稿)
などになると文字認識率が低下する場合があり、
・フォントの識別
・文字と非文字の区別
・確実なリジェクト
・背景下の文字
・見出しなどの飾り文字
などの文字認識は、難しいと言われてきましたが、最近では画像処理技術の進歩により、徐々に可能となりつつあります。
すなわち、新聞のように複雑な段組みで、文字と文字の間隔も狭い文書については難しく、普通に印字したワープロ原稿などのように、文字と文字の間隔の空いている文書は一般に認識し易いということが言えます。
このように、現状の文字認識技術のレベルは人間と比較するとまだまだ低いところもありますが、文字認識し易い文書も世の中にはたくさんあり、技術的にも日々進化していますので、「上手に使う」ことにより、非常に便利なソフトウェアであると言えるでしょう。
様々な文字認識方式
個別文字を認識する方式は「特徴抽出」と「識別処理」に分けることができます。
「特徴抽出」は、 OCR技術解説で説明しましたように、文字の認識を安定に行うための「特徴」を抽出することであり、 「識別処理」はこの「特徴」を使って、いかに高精度に文字認識を行うかという処理です (前項では「識別処理」の例としてユークリッド距離について説明しました)。
文字認識のための「特徴」の研究は古くから行われ、いろいろな特徴が提案されています。
平成6年度に旧郵政研究所が主体となって行われた「認識アルゴリズム複合方式の研究」によれば、
・拡張セル特徴(当社)
・加重方向ヒストグラム(三重大学)
・外郭方向寄与度特徴(NTT)
等が、すぐれた方式として評価されています。
これらの方式を簡単に説明すると「拡張セル特徴」方式(参考文献2)は、 図13に示すように、文字線に対して直角方向成分を抽出して、これを文字線の方向成分として図8に示す処理をしており、 「加重方向ヒストグラム」方式(参考文献3)は、図14に示すように文字線の輪郭線成分を抽出して、 これを文字線の方向成分として図8に示す処理をしています。
また、「外郭方向寄与度特徴」方式(参考文献4)は、文字線を構成する黒点の連結長である 「方向寄与度特徴」を図15に示すように、基本特徴として抽出し、これを文字線の方向成分としています。
このように、これらの「特徴」はすべてどこかの時点で方向成分に分解した特徴となっています。
▼図8--●特徴抽出

▼図13--●拡張セル特徴方式の初期段階で抽出されるエッジ特徴 ▼図14--●加重方向ヒストグラム方式の初期段階で抽出される輪郭特徴

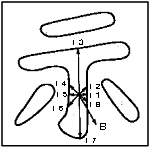
文字内の黒点Bにおいて、8方向に触手を伸ばして求まる黒点の連結長li(i=1~8)を用いて、

で定義されます。
▼図15--●方向寄与度特徴
一方、「識別処理」としては
・シティブロック距離
・ユークリッド距離
・線形識別関数
・部分空間法
・KNN法
・ベイズ識別法
・ニューラルネットによる方法
等の方式が研究、実用化されています。
「シティブロック距離」は図10に示す2次元平面間の同座標における値の差の絶対値の和として定義される、最も単純な方法です。
▼図10●ユークリッド距離(D)

「線形識別関数」や「部分空間法」、「ベイズ識別法」は、統計的な識別関数といわれ、標準パターンを作成する際に、大量のデータを使用して、認識する文字種ごとの細かな相異を判別できるような判別境界にあたるデータを抽出してこれを標準パターンとする方式です。
また、「KNN法」は、文字の変形などの「ばらつき」を複数の標準パターンを用意して解決する方式であり、「ニューラルネットによる方法」は、多数のニューロンが複数層あるようなネットワークを構成し、このネットワークに大量の文字パターンの特徴をあらかじめ学習させておき、これを使って文字の識別を行う方式です。
最近では、CPU性能の向上により、計算量の多い識別処理もパソコンで実現可能になっています。
当社は、OCRソフトの認識性能を人間に近づけていくために、改善を続けています。
「特徴抽出」は、 OCR技術解説で説明しましたように、文字の認識を安定に行うための「特徴」を抽出することであり、 「識別処理」はこの「特徴」を使って、いかに高精度に文字認識を行うかという処理です (前項では「識別処理」の例としてユークリッド距離について説明しました)。
文字認識のための「特徴」の研究は古くから行われ、いろいろな特徴が提案されています。
平成6年度に旧郵政研究所が主体となって行われた「認識アルゴリズム複合方式の研究」によれば、
・拡張セル特徴(当社)
・加重方向ヒストグラム(三重大学)
・外郭方向寄与度特徴(NTT)
等が、すぐれた方式として評価されています。
これらの方式を簡単に説明すると「拡張セル特徴」方式(参考文献2)は、 図13に示すように、文字線に対して直角方向成分を抽出して、これを文字線の方向成分として図8に示す処理をしており、 「加重方向ヒストグラム」方式(参考文献3)は、図14に示すように文字線の輪郭線成分を抽出して、 これを文字線の方向成分として図8に示す処理をしています。
また、「外郭方向寄与度特徴」方式(参考文献4)は、文字線を構成する黒点の連結長である 「方向寄与度特徴」を図15に示すように、基本特徴として抽出し、これを文字線の方向成分としています。
このように、これらの「特徴」はすべてどこかの時点で方向成分に分解した特徴となっています。
▼図8--●特徴抽出
▼図13--●拡張セル特徴方式の初期段階で抽出されるエッジ特徴 ▼図14--●加重方向ヒストグラム方式の初期段階で抽出される輪郭特徴
文字内の黒点Bにおいて、8方向に触手を伸ばして求まる黒点の連結長li(i=1~8)を用いて、
で定義されます。
▼図15--●方向寄与度特徴
一方、「識別処理」としては
・シティブロック距離
・ユークリッド距離
・線形識別関数
・部分空間法
・KNN法
・ベイズ識別法
・ニューラルネットによる方法
等の方式が研究、実用化されています。
「シティブロック距離」は図10に示す2次元平面間の同座標における値の差の絶対値の和として定義される、最も単純な方法です。
▼図10●ユークリッド距離(D)
「線形識別関数」や「部分空間法」、「ベイズ識別法」は、統計的な識別関数といわれ、標準パターンを作成する際に、大量のデータを使用して、認識する文字種ごとの細かな相異を判別できるような判別境界にあたるデータを抽出してこれを標準パターンとする方式です。
また、「KNN法」は、文字の変形などの「ばらつき」を複数の標準パターンを用意して解決する方式であり、「ニューラルネットによる方法」は、多数のニューロンが複数層あるようなネットワークを構成し、このネットワークに大量の文字パターンの特徴をあらかじめ学習させておき、これを使って文字の識別を行う方式です。
最近では、CPU性能の向上により、計算量の多い識別処理もパソコンで実現可能になっています。
当社は、OCRソフトの認識性能を人間に近づけていくために、改善を続けています。
参考文献
| 参考文献一覧 | |
| (1)秋山、増田:「周辺分布、線密度、外接矩形特徴を併用した文書画像の領域分割」 | |
| ■ | 電子情報通信学会論文誌(D)、Vol.J69,No.8(1986) |
|
|
|
| (2)岡:「セル特徴を用いた手書き漢字の認識」 | |
| 電子情報通信学会論文誌(D)、Vol.J66,No.1(1983) | |
|
|
|
| (3)鶴岡、栗田他:「加重方向ヒストグラム法による手書き漢字・ひらがな認識」 | |
| 電子情報通信学会論文誌(D)、Vol.J70,No.7(1987) | |
|
|
|
| (4)萩田、内藤他:「外郭方向寄与度特徴による手書き漢字の識別」 | |
| 電子情報通信学会論文誌(D)、Vol.J66,No.10(1983) | |
|
|
|
| (5)森健一監修:「パターン認識」 | |
| 電子情報通信学会(1988) | |


